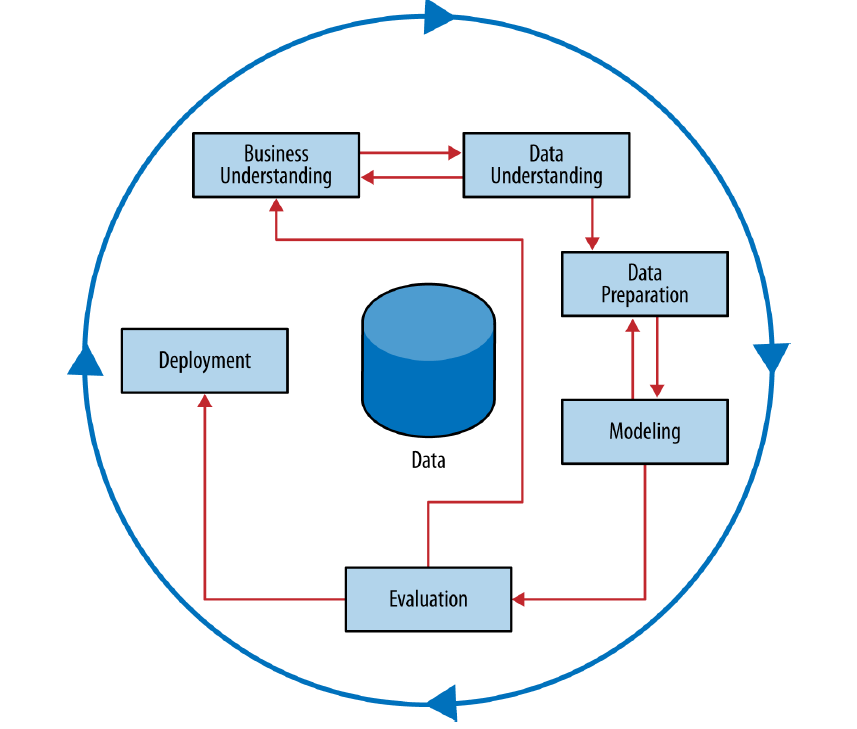
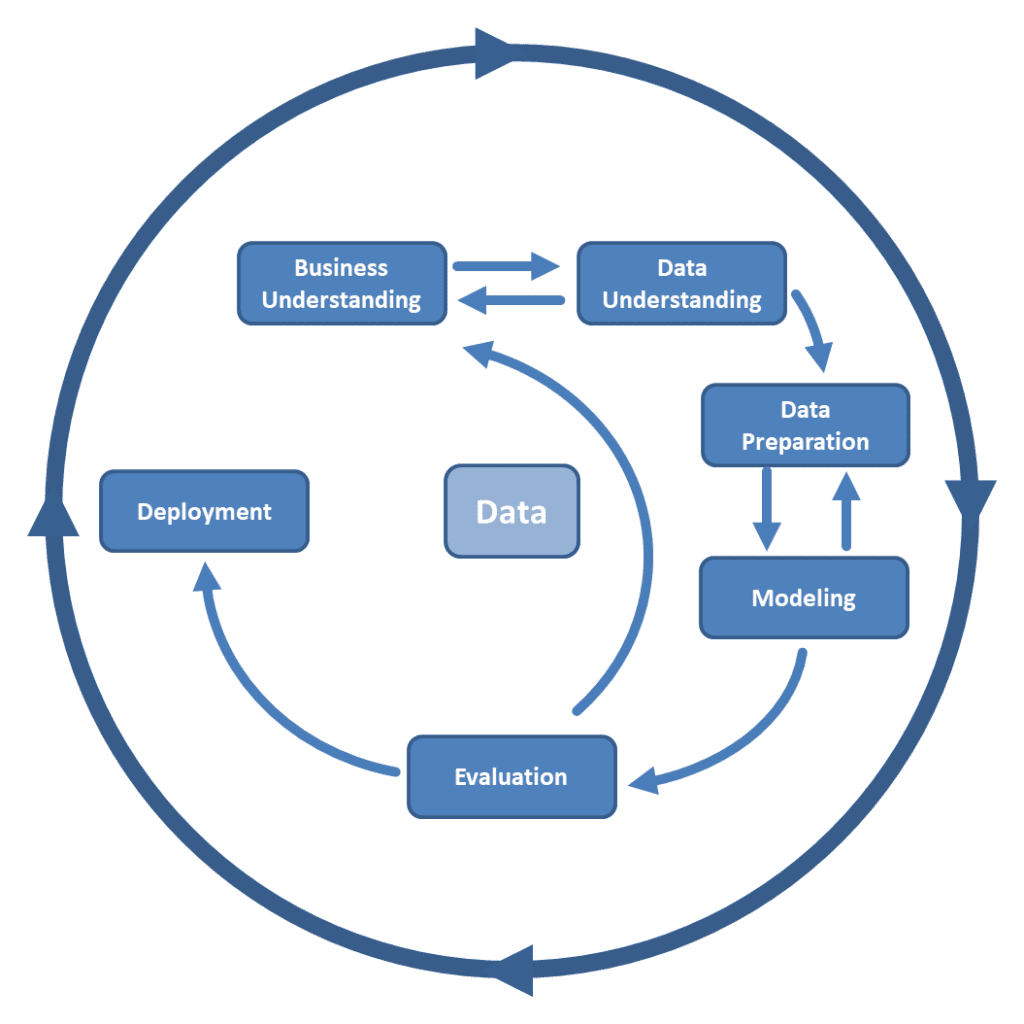
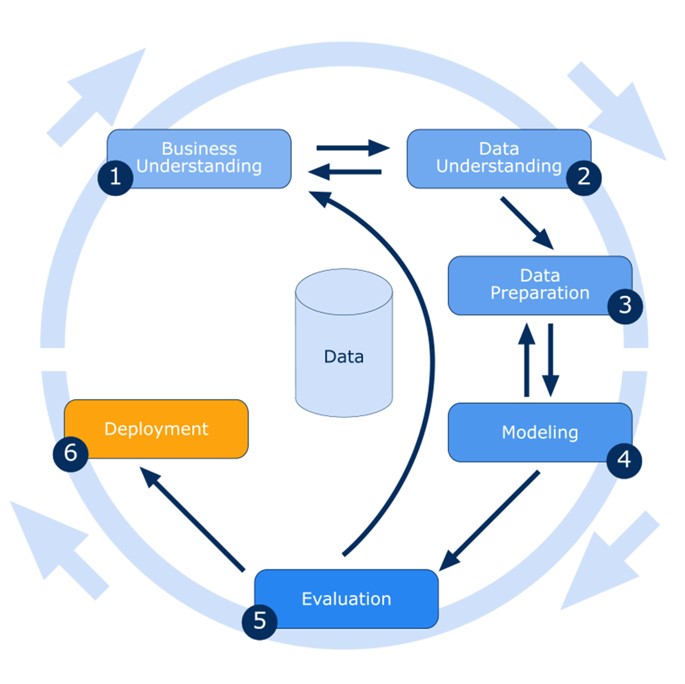
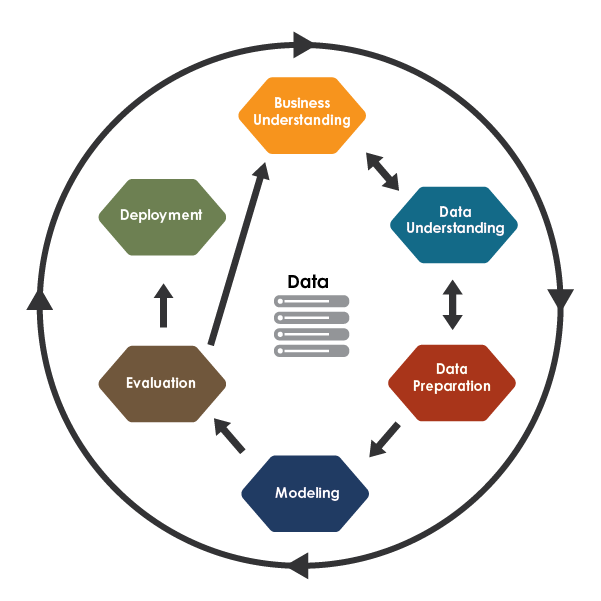
Crisp Data Mining Process

Stell dir vor, du bist ein Meisterdetektiv, aber statt eines trenchcoats und einer Lupe hast du eine riesige Menge an Daten und einen Computer. Deine Aufgabe? Muster und Geheimnisse aufdecken, die sich darin verstecken. Klingt langweilig? Denk nochmal! Dahinter steckt ein Prozess, der überraschend logisch – und manchmal sogar urkomisch – ist. Wir nennen ihn CRISP-DM, kurz für Cross-Industry Standard Process for Data Mining.
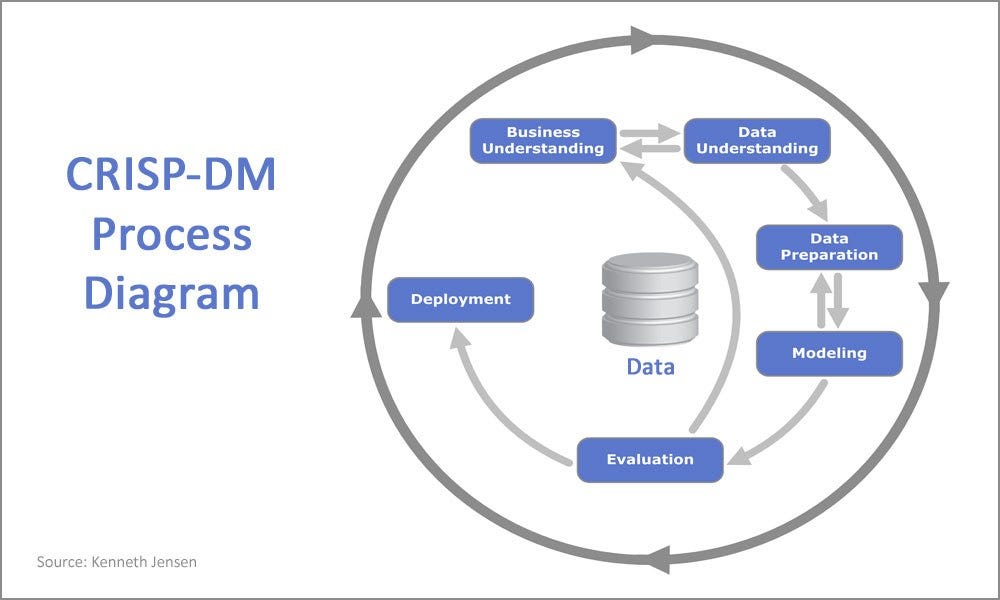
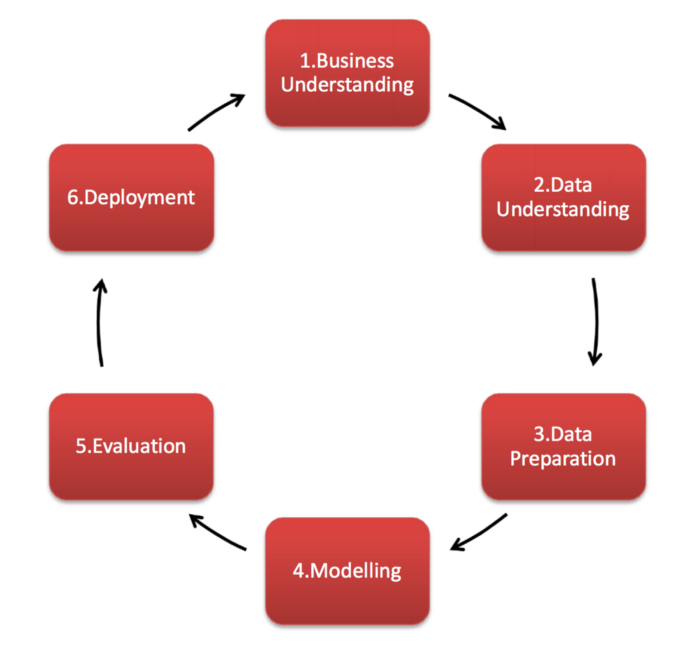
Business verstehen: Was willst du eigentlich wissen?
Alles beginnt mit einer Frage. Nicht irgendeiner Frage, sondern einer, die für dein „Unternehmen“ relevant ist. Stell dir vor, du betreibst einen Eiswagen. Deine Frage könnte sein: „An welchen Tagen verkaufe ich am meisten Eis?“ Oder vielleicht: „Welche Eissorte ist bei Kindern am beliebtesten, wenn es regnet?“ Das ist der erste, entscheidende Schritt: Business Understanding. Ohne eine klare Frage tappst du im Dunkeln, wie ein Eisverkäufer im Winter.
Dieser Schritt ist oft überraschend kompliziert. Manchmal denken Leute, sie wissen, was sie wollen, aber wenn man genauer nachfragt, stellt sich heraus, dass sie etwas ganz anderes im Sinn haben. Ein bisschen wie, wenn man „Apfelkuchen“ sagt, aber eigentlich Omas Apfelstrudel meint.
Daten sammeln: Auf Schatzsuche im Datendschungel
Jetzt wird es spannend! Du musst deine Daten sammeln. Woher bekommst du die Informationen, die du brauchst, um deine Frage zu beantworten? In unserem Eiswagen-Beispiel könnten das Verkaufszahlen, Wetterdaten, oder sogar Beobachtungen sein, wie Kinder auf verschiedene Eissorten reagieren. Dieser Schritt heißt Data Understanding. Oft stellt sich heraus, dass die Daten, die man hat, nicht die Daten sind, die man braucht. Oder noch schlimmer: Die Daten sind ein riesiges Durcheinander!
Manchmal findet man in den Daten echte Kuriositäten. Vielleicht stellst du fest, dass die Eisverkäufe an bestimmten Tagen ungewöhnlich hoch sind – nur um festzustellen, dass an diesen Tagen immer der Clown in der Nähe war, der Luftballons verteilt hat! Das ist, wo die Daten anfangen, Geschichten zu erzählen.
Daten säubern: Der große Frühjahrsputz
Daten sind selten perfekt. Oft sind sie unvollständig, fehlerhaft oder einfach nur seltsam formatiert. Dieser Schritt, Data Preparation, ist wie ein großer Frühjahrsputz. Du entfernst doppelte Einträge, korrigierst Fehler und bringst die Daten in eine Form, in der der Computer sie versteht.
Das kann eine mühsame Aufgabe sein, aber sie ist unerlässlich. Stell dir vor, du willst einen Kuchen backen, aber dein Rezept sagt: "1 Ei, 2 Tassen Mehl... und ein Dinosaurier." Du müsstest den Dinosaurier wohl oder übel entfernen, bevor du weitermachen kannst. Genauso ist es mit den Daten.
Modelle bauen: Auf der Suche nach dem Muster
Jetzt kommt der Spaß! Mit den sauberen Daten kannst du beginnen, Modelle zu bauen. Das bedeutet, dass du verschiedene Algorithmen und Techniken anwendest, um Muster und Beziehungen in den Daten zu finden. Dieser Schritt heißt Modeling. Es ist wie ein Detektiv, der verschiedene Theorien testet, um den Täter zu finden.
Es gibt unzählige verschiedene Modellierungstechniken, und welche am besten geeignet ist, hängt von deiner Frage und deinen Daten ab. Manchmal funktioniert eine einfache Methode am besten, manchmal braucht man etwas Komplexeres. Es ist ein bisschen wie die Wahl des richtigen Werkzeugs für den Job. Du würdest ja auch nicht mit einem Hammer versuchen, eine Schraube einzudrehen, oder?
Bewertung: Stimmt das, was das Modell sagt?
Nachdem du ein Modell gebaut hast, musst du es bewerten. Sagt es wirklich etwas Sinnvolles aus? Ist es zuverlässig? Oder ist es nur ein Zufallstreffer? Dieser Schritt heißt Evaluation. Du testest dein Modell auf Herz und Nieren, um sicherzustellen, dass es nicht nur gut aussieht, sondern auch funktioniert.
Manchmal stellt man fest, dass das Modell zwar technisch korrekt ist, aber in der Praxis nicht wirklich hilfreich. Vielleicht sagt es dir, dass du an Sonntagen am meisten Eis verkaufst, aber das wusstest du ja schon! Dann musst du zurück zum Reißbrett und ein neues Modell ausprobieren.
Einsatz: Ab ins wahre Leben!
Wenn du ein Modell gefunden hast, das funktioniert, kannst du es einsetzen. Das bedeutet, dass du die Erkenntnisse aus dem Modell nutzt, um Entscheidungen zu treffen. In unserem Eiswagen-Beispiel könntest du beschließen, an Sonntagen mehr Eis zu bestellen, oder du könntest eine spezielle Eissorte für Regentage entwickeln. Dieser Schritt heißt Deployment. Es ist, als würdest du dein neues Wissen nutzen, um dein Geschäft zu verbessern.
Der Einsatz kann aufregend, aber auch beängstigend sein. Manchmal funktioniert alles perfekt, manchmal geht etwas schief. Aber selbst wenn etwas schiefgeht, kannst du daraus lernen und dich verbessern. Denk dran: Data Mining ist ein iterativer Prozess. Du lernst ständig dazu und verbesserst deine Modelle. Und wer weiß, vielleicht entdeckst du ja das nächste große Geheimnis hinter den Eisverkäufen. Vielleicht ist es ja gar nicht der Clown, sondern der versteckte Rabatt auf Erdbeereis am letzten Dienstag im Monat!
Also, das nächste Mal, wenn du von Data Mining hörst, denk nicht an komplizierte Formeln und langweilige Tabellen. Denk an einen Detektiv, der im Datendschungel nach verborgenen Schätzen sucht, einen Eisverkäufer, der versucht, seine Kunden besser zu verstehen, und an die überraschenden, humorvollen und manchmal sogar herzerwärmenden Geschichten, die in den Daten stecken.