Group By Dataframe Pandas
Stell dir vor, du bist auf einem gigantischen Flohmarkt. Überall Stände, voll mit Kram! Kleidung, Bücher, seltsame Sammlerstücke, alles durcheinander. Und du suchst… sagen wir mal, alle blauen T-Shirts. Oder alle Bücher, die vor 1980 gedruckt wurden. Das wäre ein heilloses Durcheinander, oder?
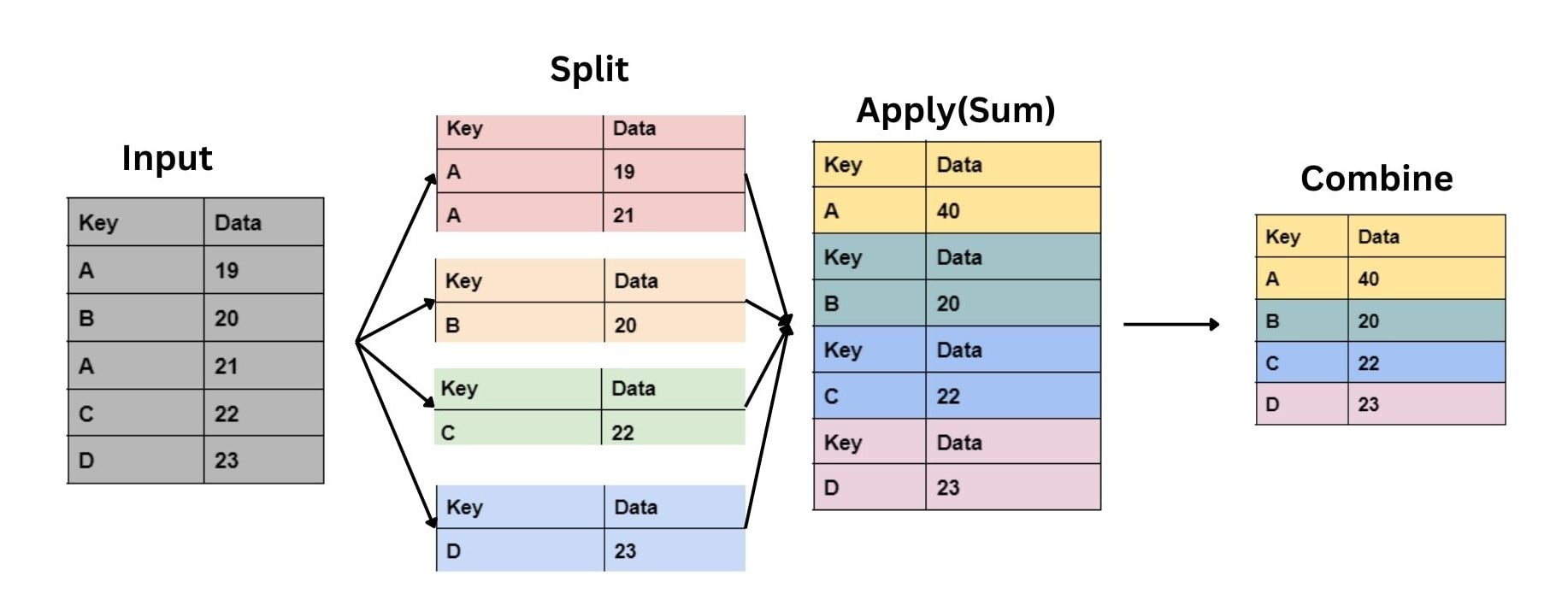
Genau hier kommt Pandas ins Spiel, genauer gesagt die Group By Funktion! Pandas ist wie ein super-ordentlicher Flohmarkt-Manager, der das ganze Chaos in wunderschöne, geordnete Kategorien verwandeln kann. Und Group By ist sein mächtigstes Werkzeug!
Stell dir vor, wir haben eine Tabelle mit allen verkauften Artikeln auf dem Flohmarkt. Jede Zeile ist ein Artikel, und die Spalten sind zum Beispiel: 'Artikel', 'Farbe', 'Preis', 'Verkäufer'.
Gruppieren nach Farbe: Blaue Glückseligkeit!
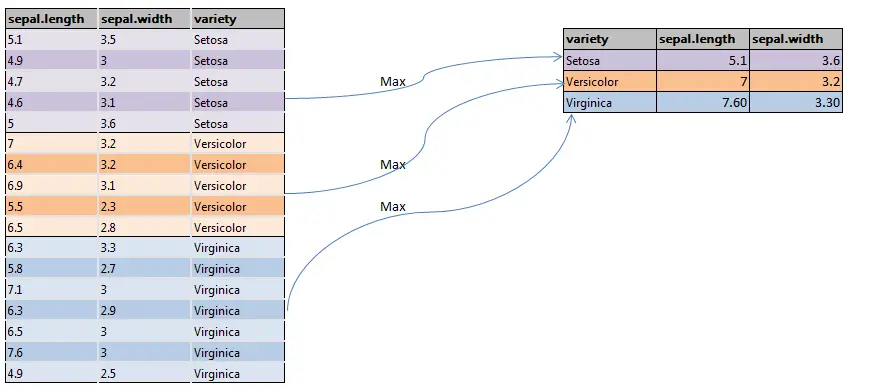
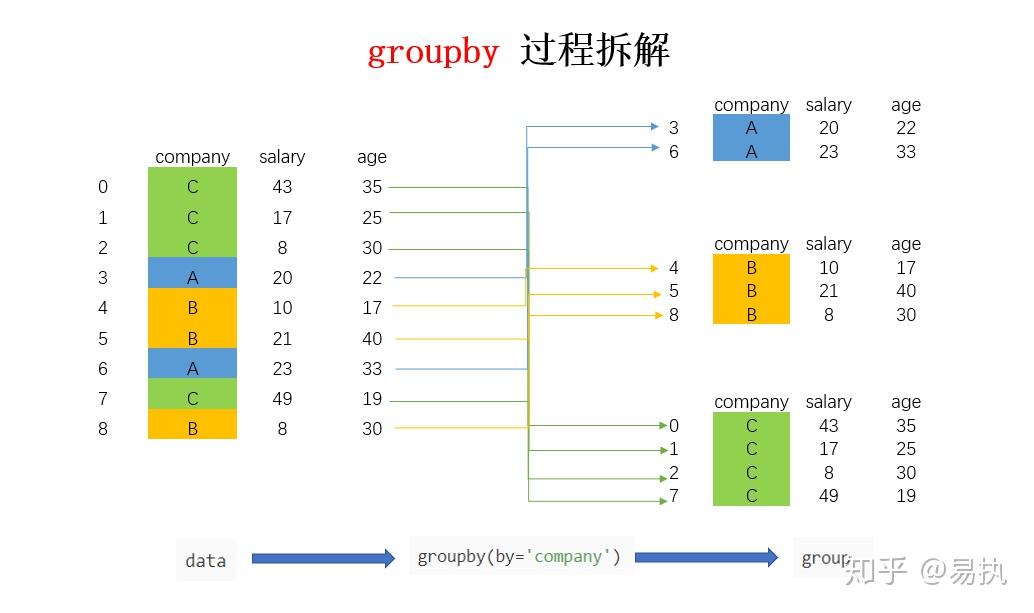
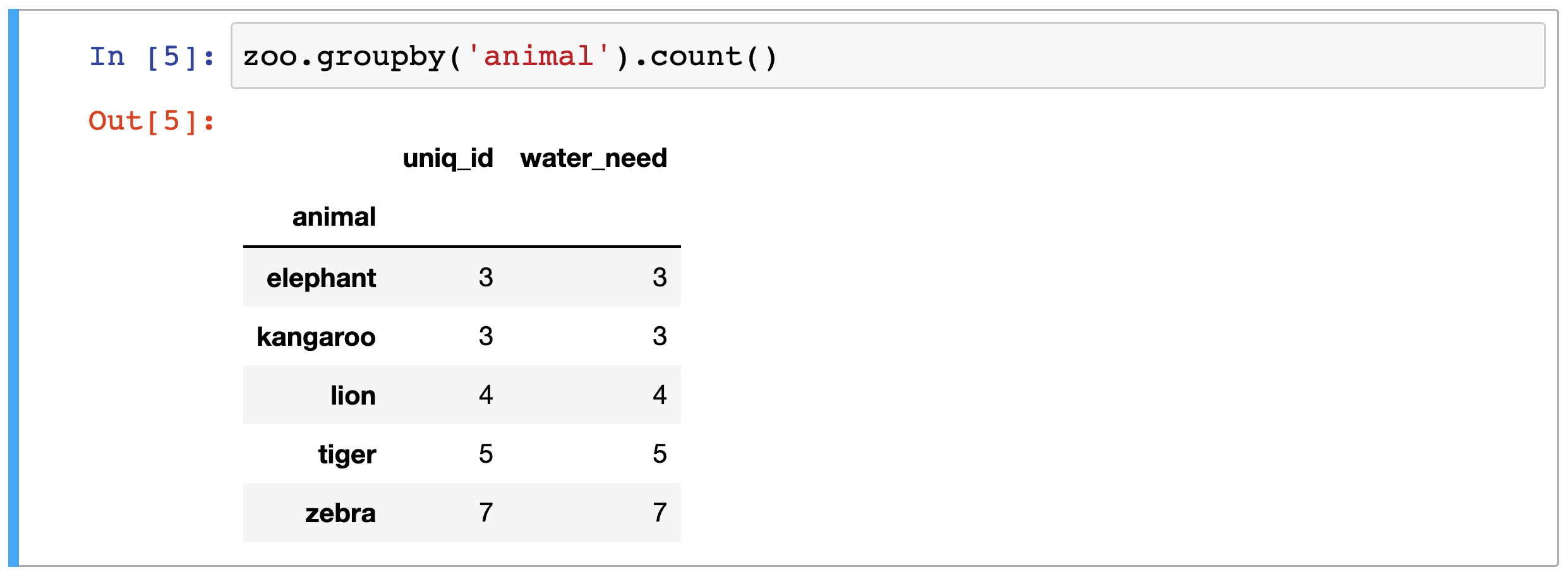
Wir wollen wissen, wie viele Artikel in jeder Farbe verkauft wurden. Zack! Mit Group By verwandeln wir diese chaotische Tabelle in eine blitzsaubere Statistik. Wir sagen Pandas: "Hey, gruppiere mir das mal nach 'Farbe' und zähl dann, wie viele Artikel in jeder Gruppe sind!"
Das Ergebnis? Eine Tabelle, die dir sofort sagt: 15 blaue T-Shirts, 8 rote Vasen, 3 grüne Gummienten. Boom! Information overload adé, hallo kristallklare Einsichten!
Gruppieren nach Verkäufer: Wer ist der Flohmarkt-König?
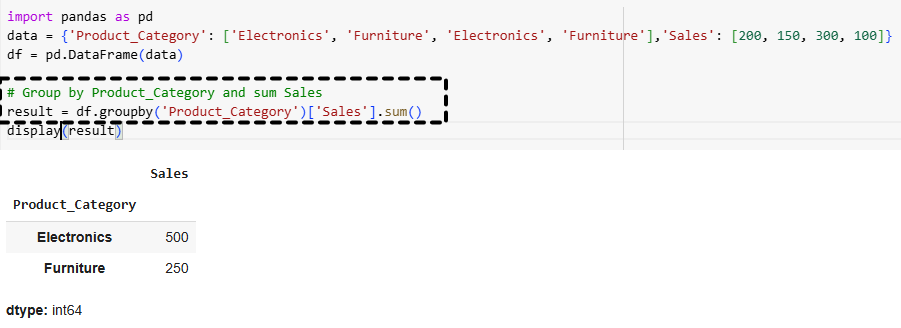
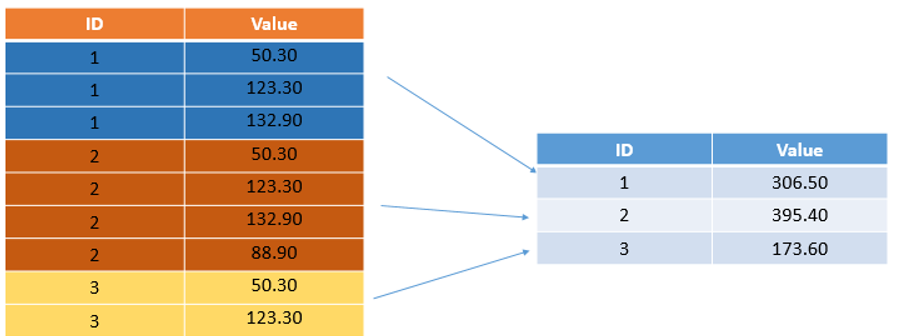
Aber warte, es wird noch besser! Wir wollen wissen, welcher Verkäufer am meisten Umsatz gemacht hat. Kein Problem für unseren Pandas-Profi! Wir gruppieren nach 'Verkäufer' und berechnen die Summe der 'Preis'-Spalte für jede Gruppe.
Plötzlich wissen wir: Frau Schmidt hat 500€ eingenommen, Herr Müller 320€ und die kleine Lisa, die ihre alten Spielsachen verkauft, immerhin auch 50€. Wow! Wir können sogar noch weiter gehen und die Durchschnittspreise pro Verkäufer berechnen. Pandas ist einfach unersättlich!
Ein bisschen mehr Detail: Farbe und Verkäufer Kombi!
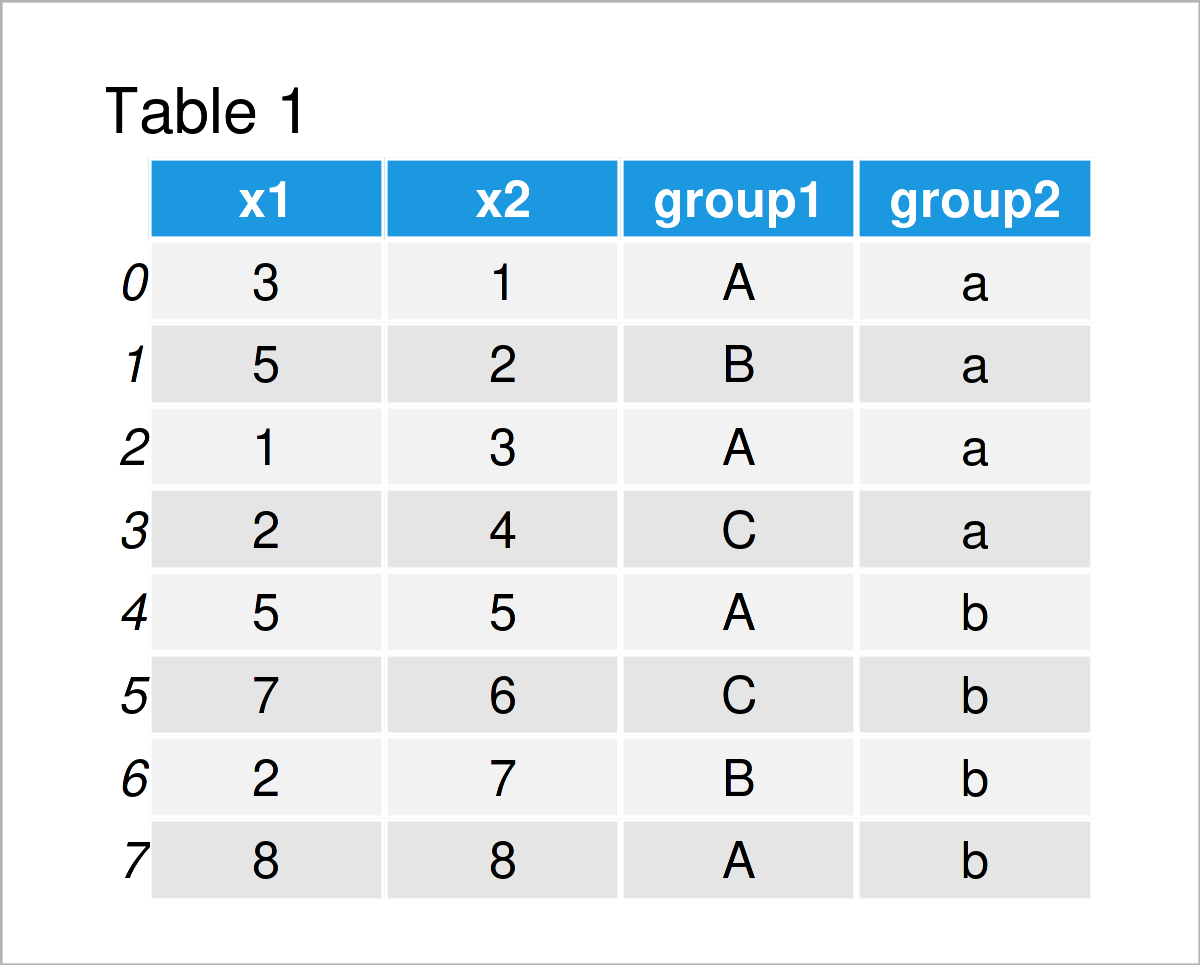
Okay, jetzt wird es richtig spannend. Wir wollen wissen, wie viele blaue Artikel Frau Schmidt verkauft hat. Group By kann auch mehrere Spalten auf einmal verarbeiten! Wir gruppieren nach 'Verkäufer' UND 'Farbe'.
Das Ergebnis? Eine detaillierte Aufschlüsselung: Frau Schmidt hat 3 blaue T-Shirts und 2 rote Vasen verkauft. Herr Müller hat 5 grüne Gummienten und 1 blaues Buch verkauft. Lisa hat… naja, Lisa hat nur ein paar bunte Legosteine verkauft. Aber immerhin!
Merke: Mit Group By kannst du deine Daten in so viele kleine Häppchen zerlegen, bis du genau die Information hast, die du brauchst. Es ist wie ein Schweizer Taschenmesser für Daten!
Das Sahnehäubchen: Aggregationsfunktionen!
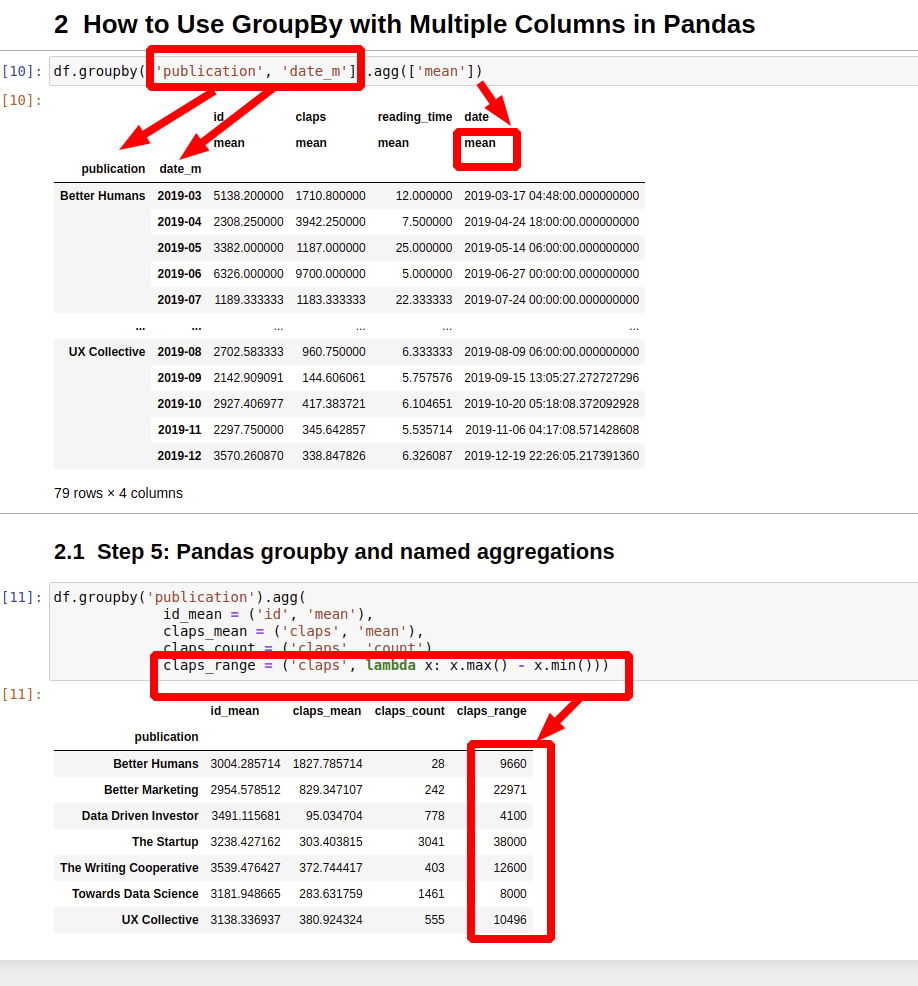
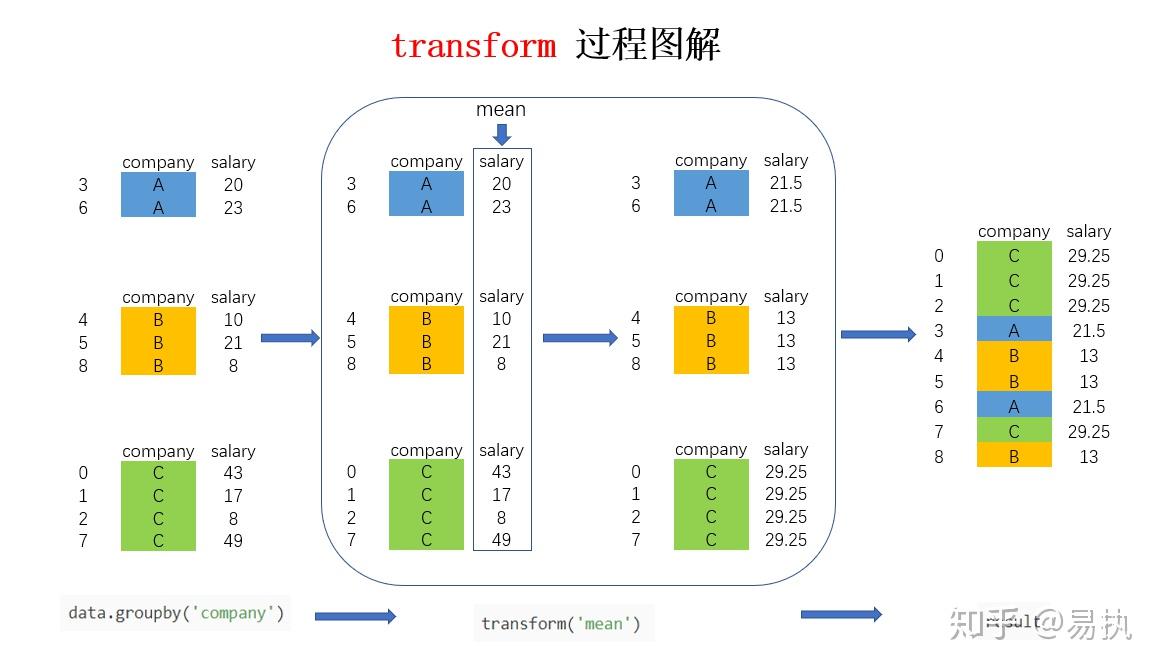
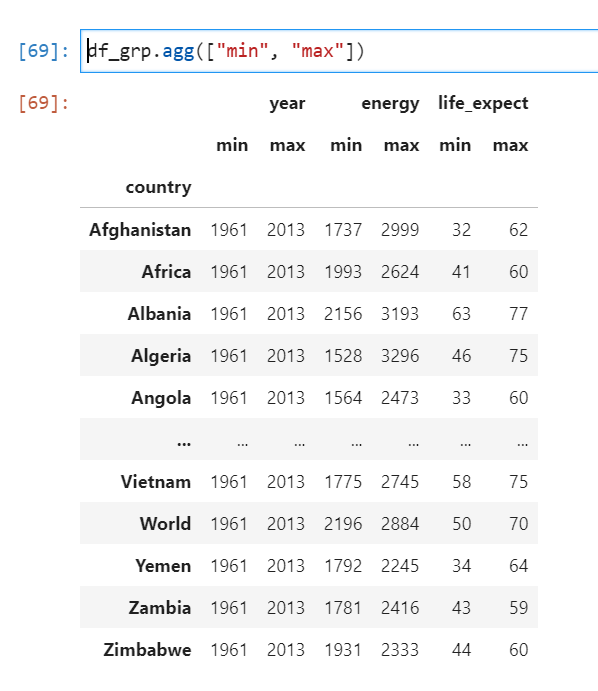
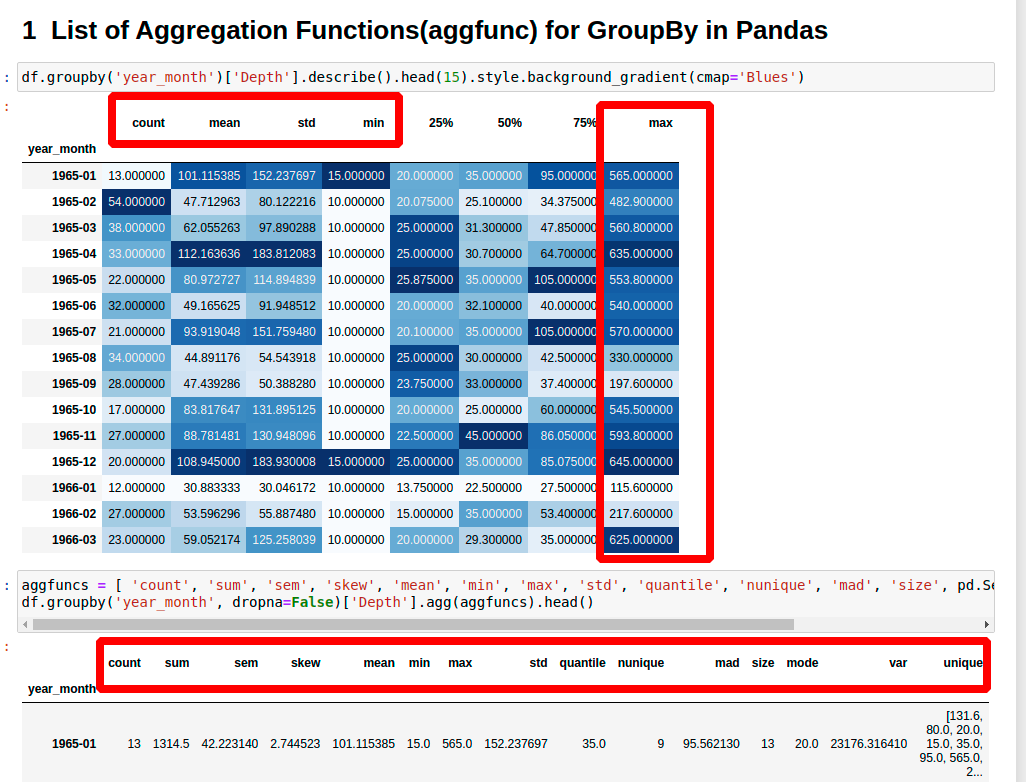
Aber das ist noch nicht alles! Group By kann noch viel mehr als nur zählen und summieren. Es kann den Durchschnitt berechnen (mean), den Minimalwert finden (min), den Maximalwert finden (max), die Standardabweichung berechnen (std)… die Liste ist endlos!
Stell dir vor, wir wollen den Durchschnittspreis für jeden Artikeltyp herausfinden. Wir gruppieren nach 'Artikel' und verwenden die mean-Funktion auf der 'Preis'-Spalte. Zack! Wir wissen, dass T-Shirts im Durchschnitt 15€ kosten, Vasen 20€ und Gummienten… naja, Gummienten sind halt billig.
Und das Beste daran? Du kannst all diese Aggregationsfunktionen in einem einzigen Schritt kombinieren! Wir können gleichzeitig den Durchschnittspreis, den Minimalpreis und den Maximalpreis für jeden Artikeltyp berechnen. Pandas ist ein wahres Rechengenie!
Also, das nächste Mal, wenn du mit unübersichtlichen Datenmengen konfrontiert bist, denk an Pandas und seine magische Group By-Funktion. Sie wird dir helfen, das Chaos zu bändigen und wertvolle Erkenntnisse zu gewinnen. Und wer weiß, vielleicht findest du ja sogar das perfekte blaue T-Shirt auf deinem digitalen Flohmarkt!
Vergiss nicht: Group By ist dein Freund und Helfer im Daten-Dschungel! Also, ran an die Daten und lass die Gruppierung beginnen!