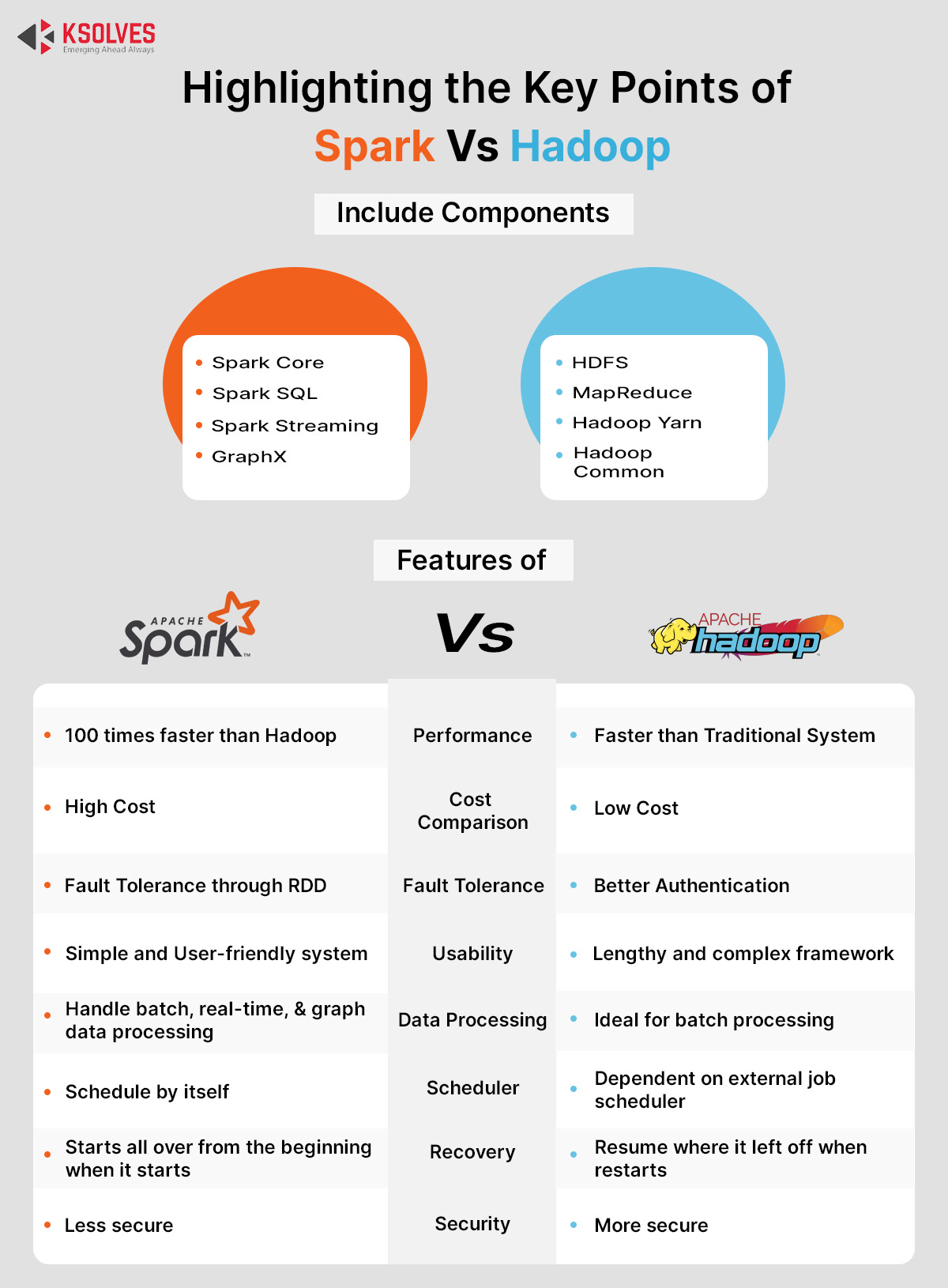
Spark Advantages Over Hadoop

Stell dir vor, Hadoop und Spark sind zwei unglaublich fleißige Bäcker. Beide können Berge von Teig verarbeiten und daraus leckere Brötchen backen. Aber sie machen es auf unterschiedliche Weise. Und stell dir vor, es geht nicht nur um Brötchen, sondern um riesige Datenmengen, die analysiert werden müssen – das ist die Welt von Hadoop und Spark!
Hadoop: Der gemütliche, zuverlässige Bäckermeister
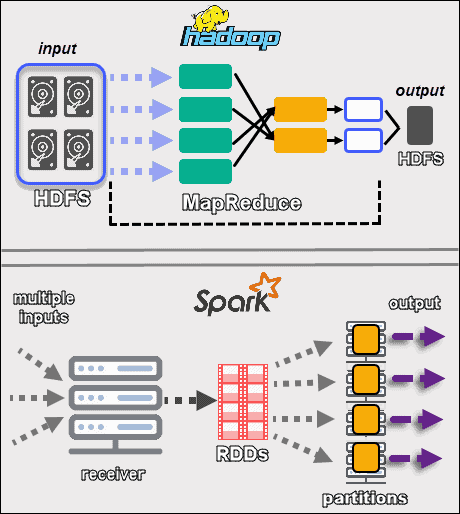
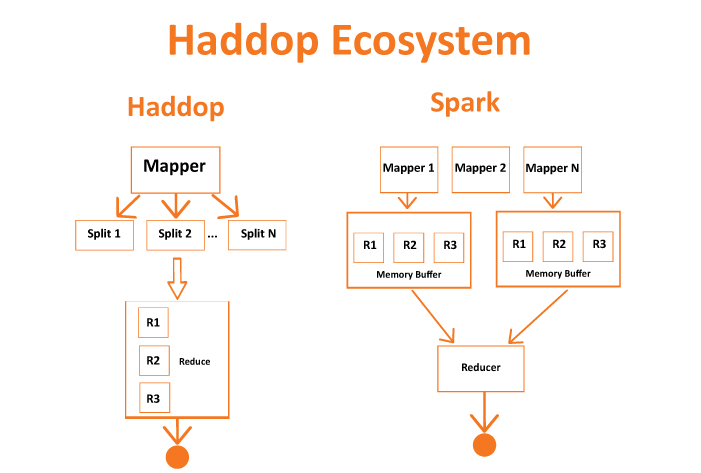
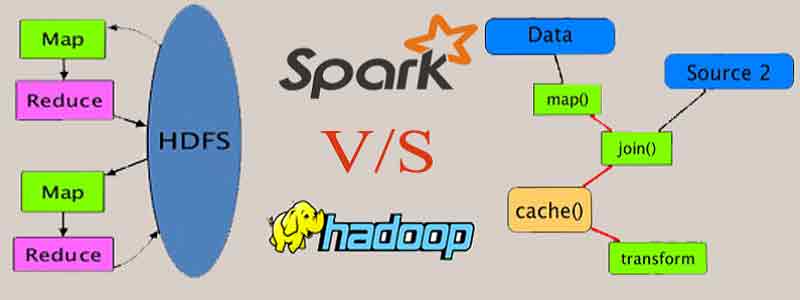
Hadoop ist wie der alteingesessene Bäckermeister, der sein Handwerk von der Pike auf gelernt hat. Er hat eine riesige Backstube und ist Experte darin, große Mengen an Teig zu lagern und zu verarbeiten. Er arbeitet sehr sorgfältig und zuverlässig, aber er nimmt sich auch Zeit. Jede Zutat wird einzeln überprüft, jeder Teigschritt genauestens dokumentiert. Wenn du eine riesige Hochzeitstorte backen musst, ist Hadoop dein Mann! Er zerlegt die Aufgabe in viele kleine Teile und verteilt sie an seine fleißigen Helfer. Diese Helfer arbeiten parallel, jeder an seinem Stück Teig. Am Ende werden alle Teile wieder zusammengesetzt – fertig ist die Hochzeitstorte!
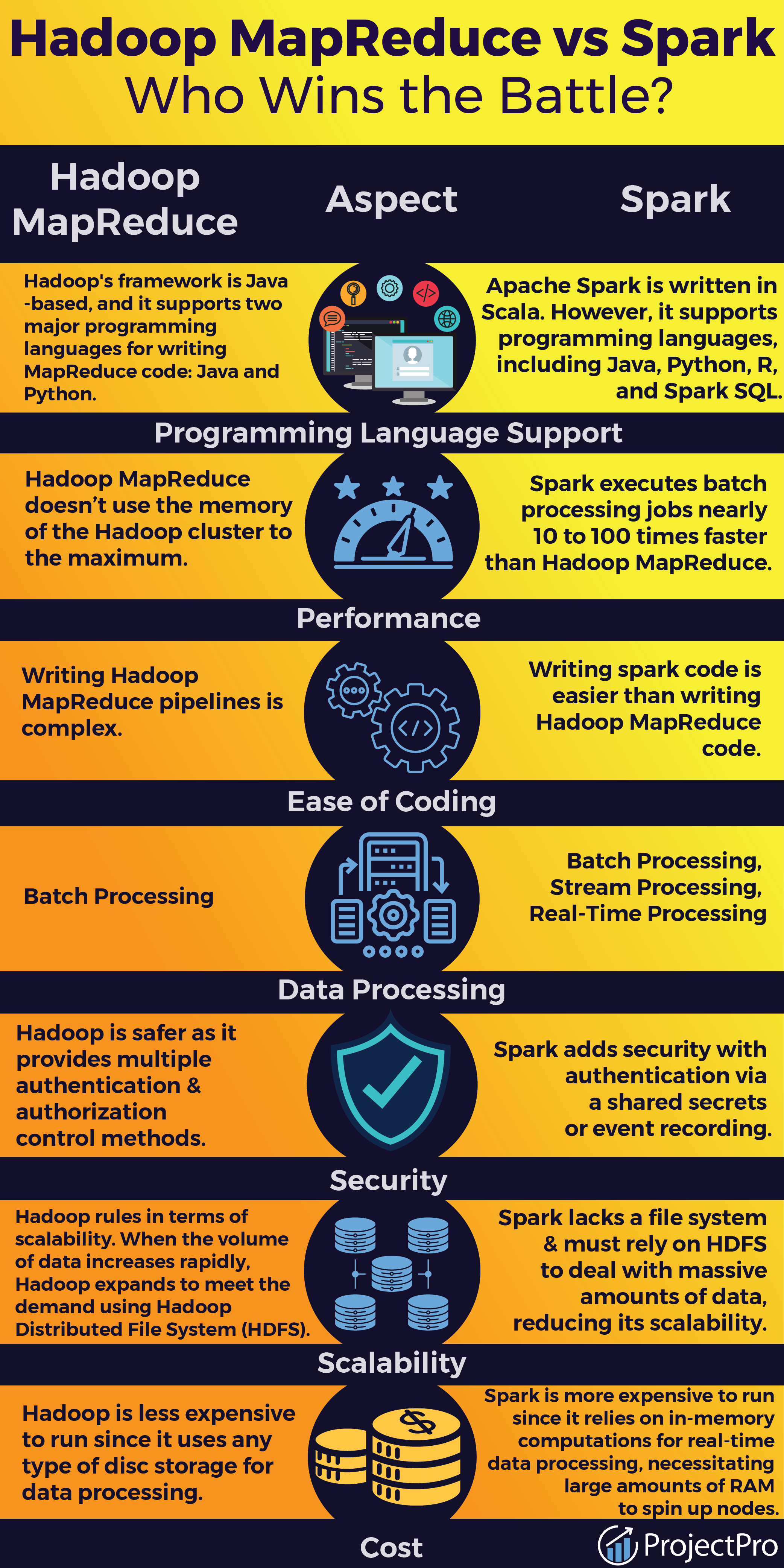
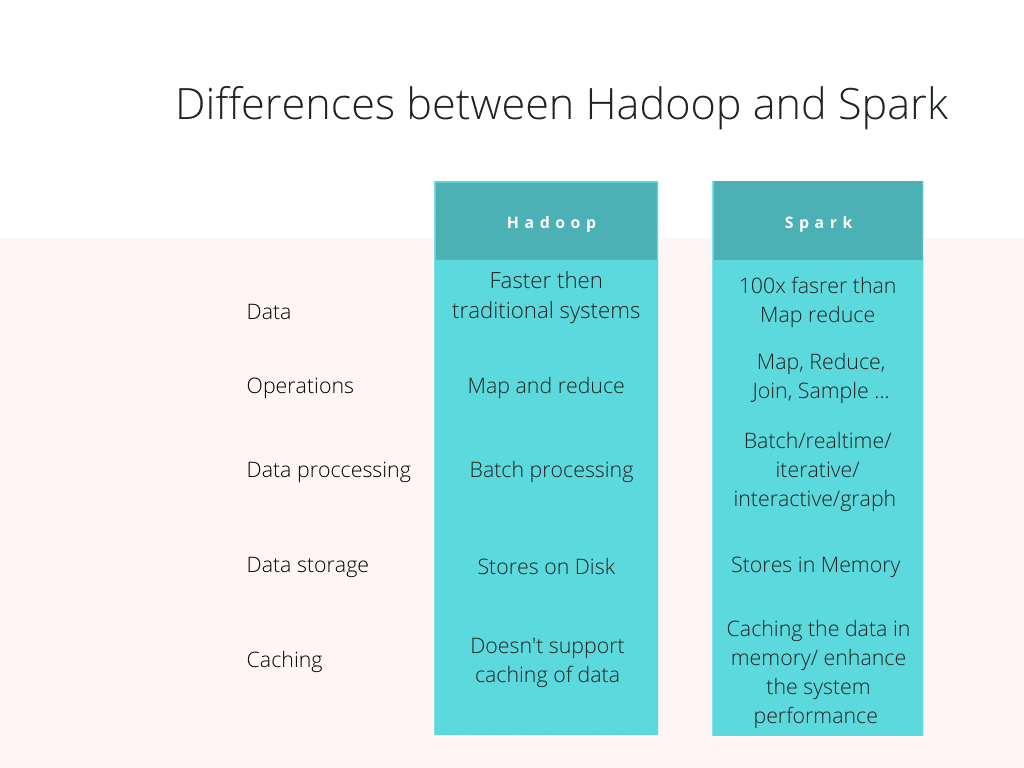
Das tolle an Hadoop: Er kann mit fast jeder Art von Daten umgehen, egal ob es sich um Text, Bilder oder Videos handelt.
Hadoops kleine Eigenheiten
Allerdings hat Hadoop auch seine kleinen Eigenheiten. Er mag es nicht, wenn man ihm zu viele Aufgaben auf einmal gibt. Jede Aufgabe wird einzeln abgearbeitet, und das dauert eben seine Zeit. Stell dir vor, du bittest ihn, zuerst Brötchen zu backen und dann noch schnell ein paar Kuchen zu dekorieren. Er wird die Brötchen backen, dann alles aufräumen und erst danach mit den Kuchen anfangen. Und wehe dem, der ihn drängt! Er ist ein Meister seines Fachs und lässt sich nicht hetzen.
Spark: Der flinke, innovative Jungbäcker
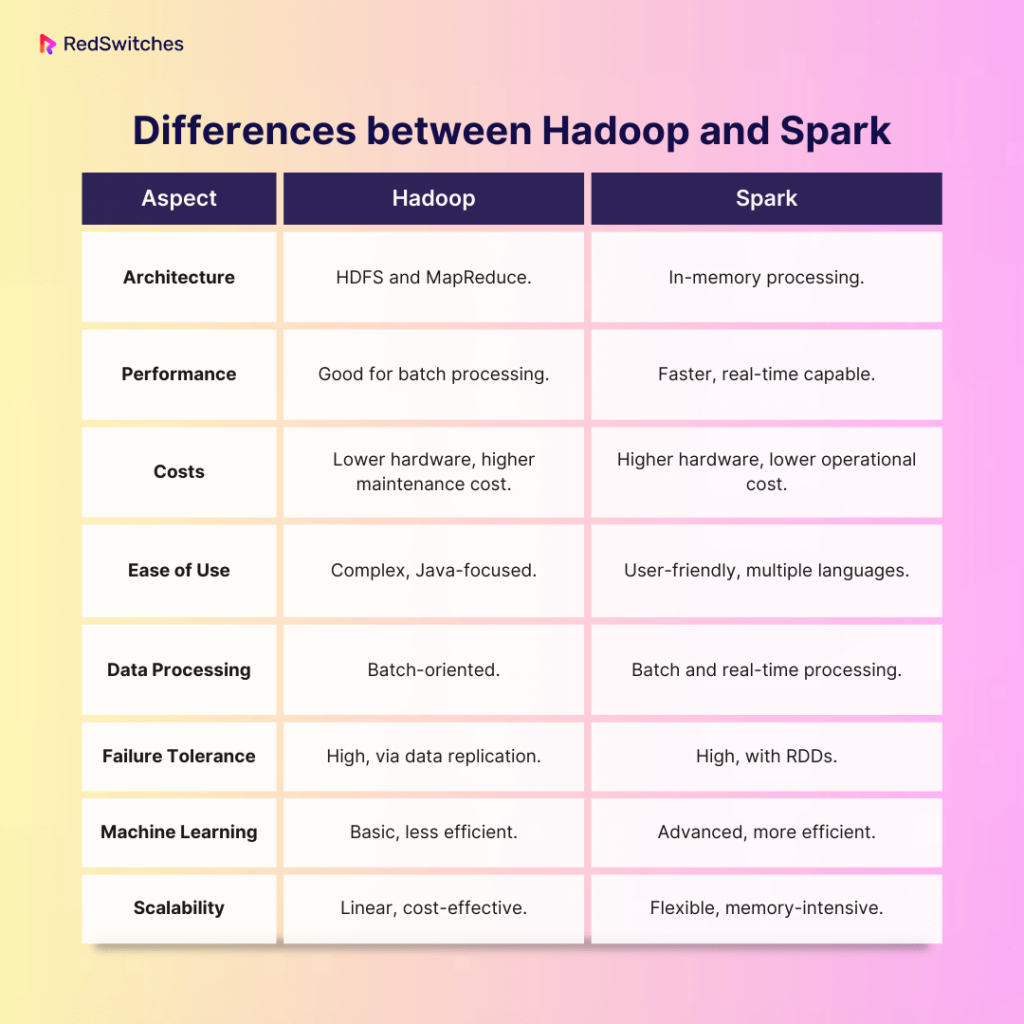
Jetzt kommt Spark ins Spiel. Er ist wie der junge, innovative Bäcker, der mit neuen Techniken experimentiert. Er hat zwar auch eine Backstube, aber die ist viel moderner eingerichtet. Er hat nicht nur einen Ofen, sondern gleich mehrere, und er verwendet ausgeklügelte Maschinen, um den Teig schneller zu verarbeiten. Spark hat einen Riesenvorteil: Er kann sich Daten im "In-Memory"-Modus merken. Das bedeutet, er speichert die Daten nicht immer wieder auf der Festplatte ab, sondern behält sie im Arbeitsspeicher. Das ist, als würde er sich die Zutaten und Arbeitsschritte im Kopf merken, anstatt sie jedes Mal in einem Rezeptbuch nachzulesen. Dadurch kann er viel schneller arbeiten.
Spark denkt mit!
Spark ist auch sehr intelligent. Er plant seine Arbeitsschritte im Voraus und optimiert sie. Stell dir vor, du bittest ihn, zuerst Brötchen zu backen und dann noch schnell ein paar Kuchen zu dekorieren. Er wird die beiden Aufgaben so kombinieren, dass sie möglichst effizient ablaufen. Vielleicht backt er die Brötchen, während die Zutaten für die Kuchen vorbereitet werden. Oder er dekoriert die Kuchen, während die Brötchen abkühlen. Er denkt mit und spart Zeit.
Ein kleines Beispiel: Stell dir vor, du hast eine riesige Liste mit Kundendaten und möchtest herausfinden, welche Kunden am liebsten Schokoladenkuchen kaufen. Hadoop würde die Liste Zeile für Zeile durchgehen und für jeden Kunden prüfen, ob er Schokoladenkuchen gekauft hat. Spark hingegen würde die Liste in kleinere Teile aufteilen und sie gleichzeitig von mehreren Helfern bearbeiten lassen. Außerdem würde er sich merken, welche Kunden bereits Schokoladenkuchen gekauft haben, um die Suche zu beschleunigen.
Das Duell der Bäcker
Wer ist nun der bessere Bäcker? Das hängt ganz davon ab, was du backen möchtest. Wenn du eine riesige Hochzeitstorte backen musst und viel Wert auf Zuverlässigkeit legst, ist Hadoop die richtige Wahl. Aber wenn du schnell viele verschiedene kleine Aufgaben erledigen musst, ist Spark der bessere Kandidat. Er ist schneller, flexibler und kann sich Daten merken.
In der Welt der Datenanalyse bedeutet das: Wenn du riesige Datenmengen speichern und verarbeiten musst, aber die Geschwindigkeit nicht so wichtig ist, ist Hadoop immer noch eine gute Wahl. Aber wenn du interaktive Analysen durchführen, Machine-Learning-Modelle trainieren oder komplexe Datenströme in Echtzeit verarbeiten möchtest, dann ist Spark die bessere Option.
Manchmal arbeiten die beiden Bäcker sogar zusammen! Hadoop kann die Daten speichern und verwalten, während Spark sie analysiert und verarbeitet. Das ist wie ein Dream-Team in der Backstube!
Die Moral von der Geschicht'
Die Moral von der Geschicht': Beide Bäcker sind wertvoll, jeder auf seine Weise. Hadoop ist der zuverlässige Bäckermeister, der mit großen Mengen umgehen kann, während Spark der flinke Jungbäcker ist, der mit neuen Techniken experimentiert und schneller Ergebnisse liefert. Die Wahl hängt ganz von der Aufgabe ab. Und wer weiß, vielleicht erfinden sie ja in Zukunft noch ganz neue Backtechniken, die unsere Datenanalyse-Welt noch spannender machen!