Wie Ist Eine Dna Aufgebaut
Die Desoxyribonukleinsäure, besser bekannt als DNA, ist das Molekül, das die genetische Information in fast allen Lebewesen trägt. Sie ist der Bauplan für alles, was einen Organismus ausmacht, von der Augenfarbe bis zur Anfälligkeit für bestimmte Krankheiten. Für Neuankömmlinge oder Expats, die sich in Deutschland über biologische Grundlagen informieren möchten, bietet dieser Artikel einen klaren und verständlichen Überblick über den Aufbau der DNA.
Die Grundbausteine: Nukleotide
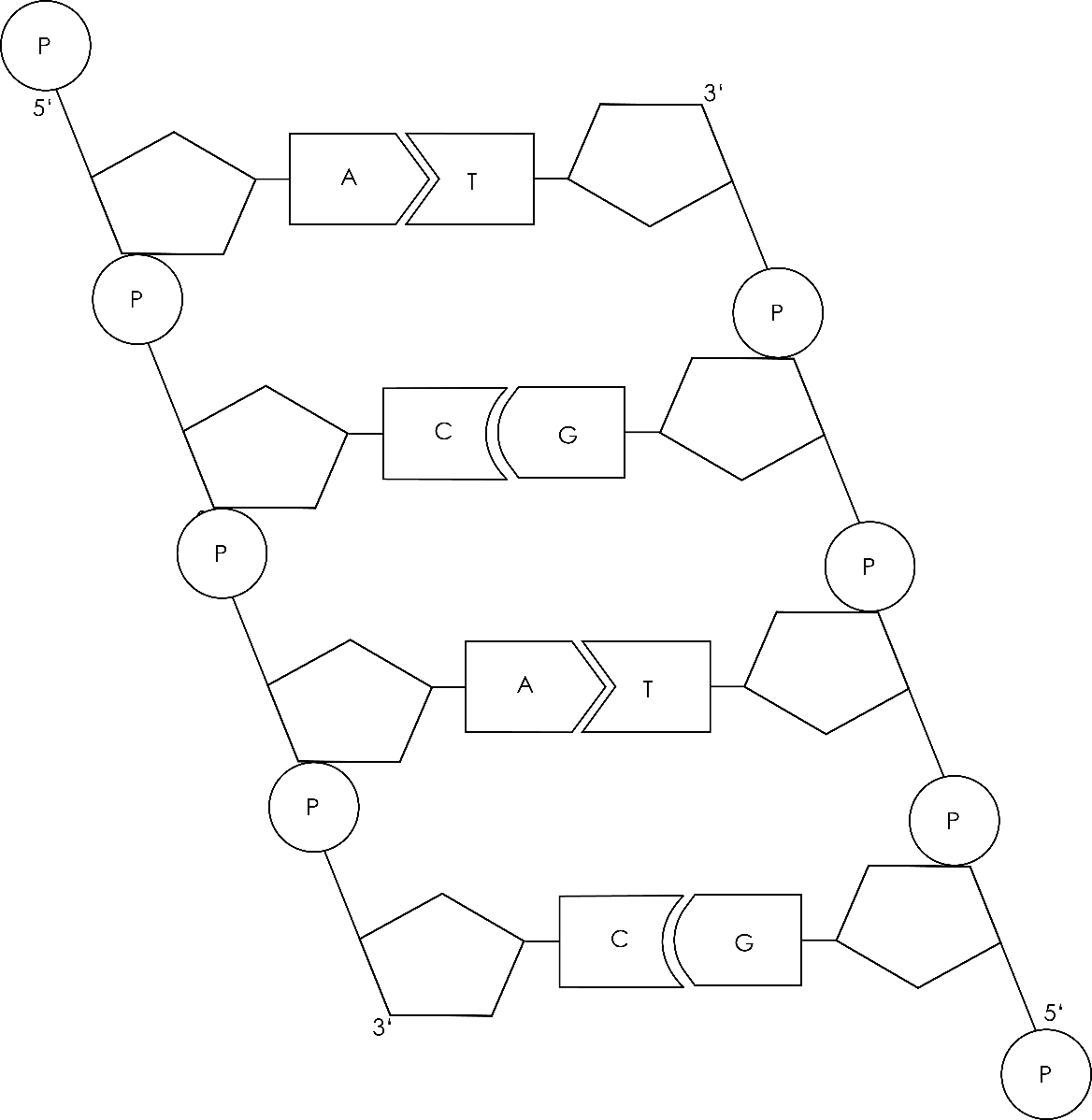
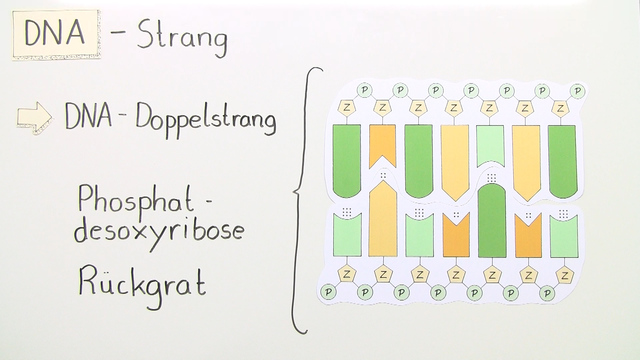
Die DNA ist wie eine lange Kette aufgebaut, deren einzelne Glieder Nukleotide genannt werden. Jedes Nukleotid besteht aus drei Hauptkomponenten:
1. Einem Zucker (Desoxyribose)
Die Desoxyribose ist ein Zucker mit fünf Kohlenstoffatomen. Sie bildet das Rückgrat des Nukleotids und verbindet sich mit den anderen Komponenten.
2. Einem Phosphatrest
Der Phosphatrest ist eine Gruppe von Atomen, die Phosphor und Sauerstoff enthält. Er verbindet ein Nukleotid mit dem nächsten und bildet so das sogenannte Zucker-Phosphat-Rückgrat der DNA-Kette. Dieses Rückgrat ist das tragende Element der DNA und verleiht ihr Stabilität.
3. Einer stickstoffhaltigen Base
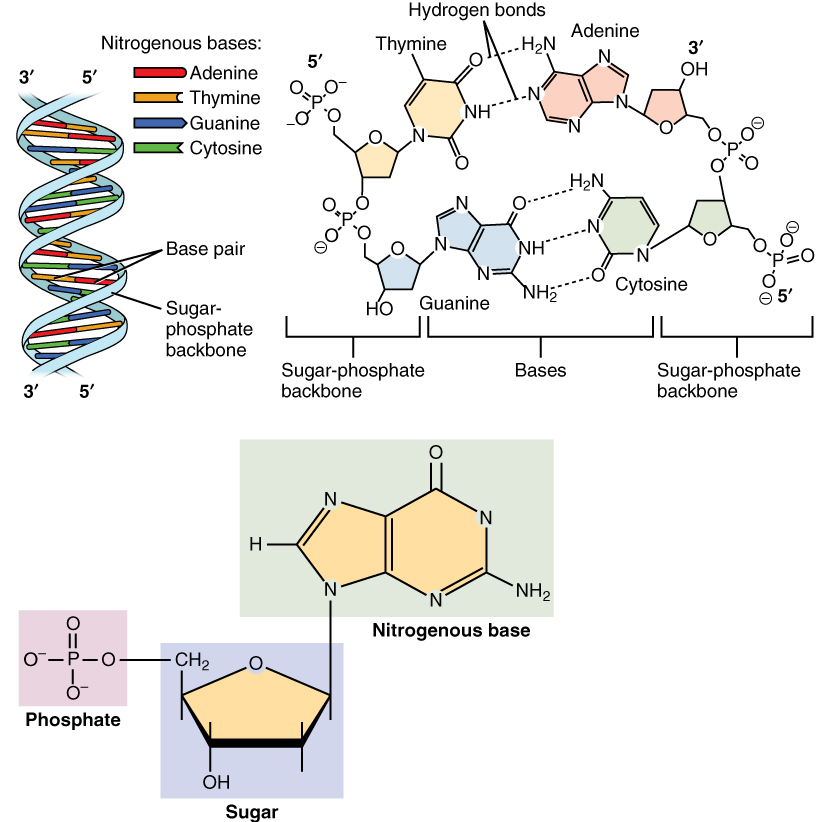
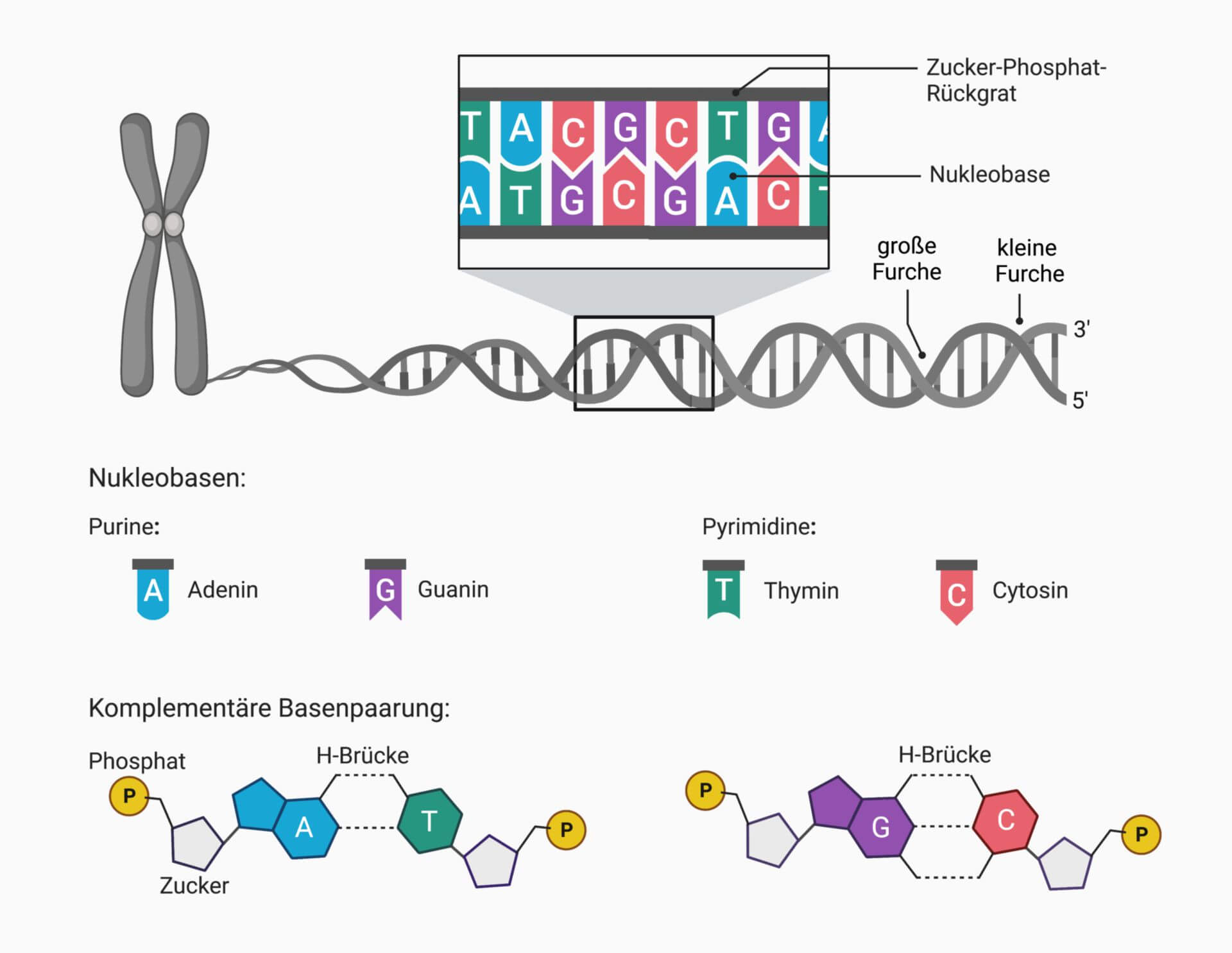
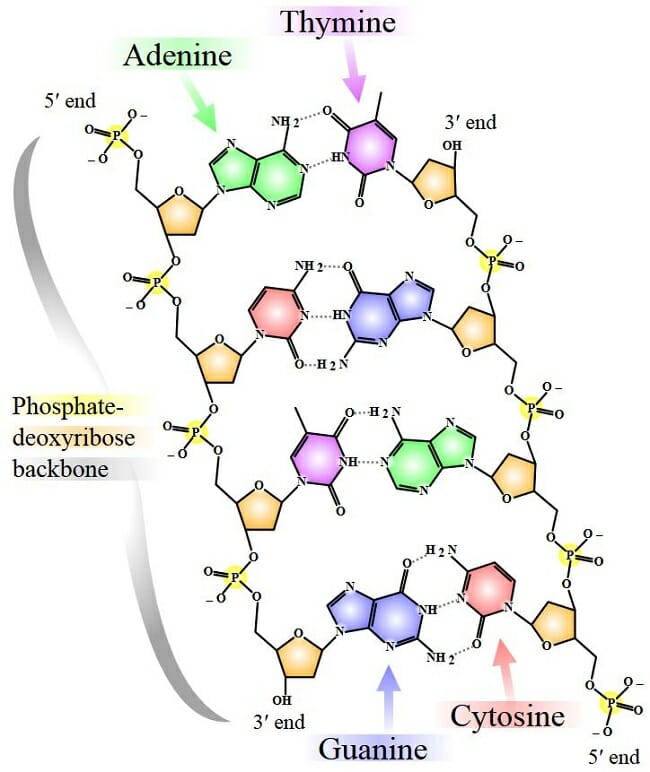
Es gibt vier verschiedene stickstoffhaltige Basen, die in der DNA vorkommen: Adenin (A), Guanin (G), Cytosin (C) und Thymin (T). Diese Basen sind der Schlüssel zur genetischen Information, denn ihre Reihenfolge bestimmt die genetischen Anweisungen. Die Basenpaare bilden die "Sprossen" der DNA-Leiter.
Die Doppelhelix-Struktur
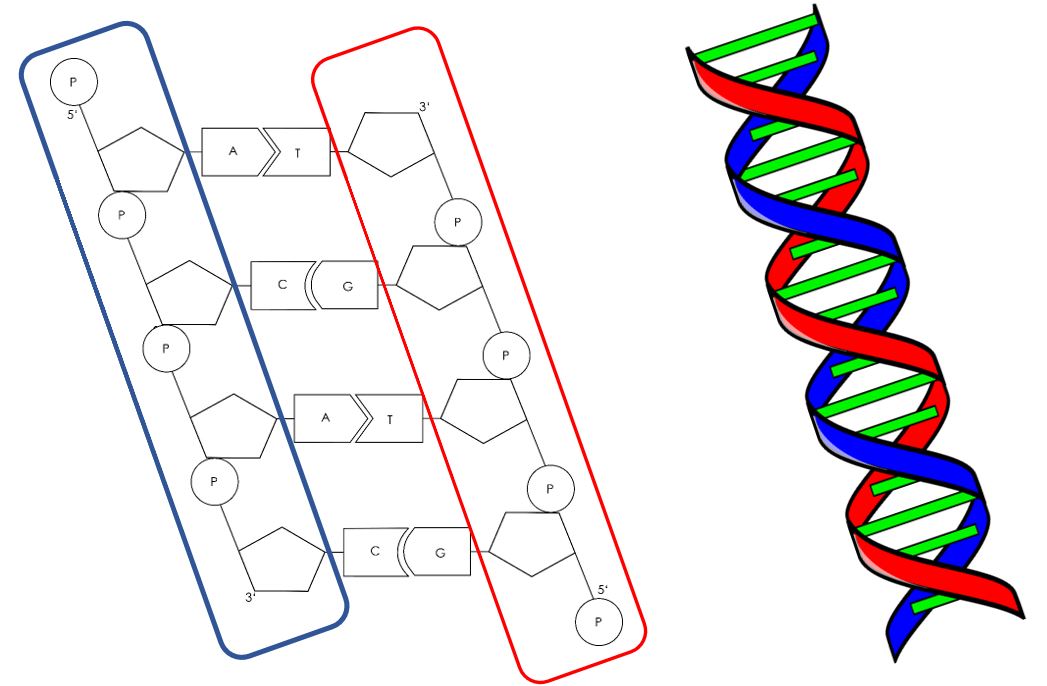
Die DNA existiert nicht als einzelne Kette, sondern als Doppelhelix. Diese Struktur wurde 1953 von James Watson und Francis Crick entdeckt, basierend auf den Arbeiten von Rosalind Franklin und Maurice Wilkins. Stellen Sie sich eine verdrehte Leiter vor. Die beiden "Holme" der Leiter werden durch die Zucker-Phosphat-Rückgrate gebildet, und die "Sprossen" werden durch die Basenpaare gebildet.
Die Doppelhelix wird durch Wasserstoffbrücken zusammengehalten, die sich zwischen den Basenpaaren bilden. Wichtig ist, dass Adenin (A) immer mit Thymin (T) ein Paar bildet, und Guanin (G) immer mit Cytosin (C). Diese spezifische Basenpaarung ist fundamental für die Replikation (Verdopplung) der DNA und die Weitergabe der genetischen Information.
Diese komplementäre Basenpaarung bedeutet, dass, wenn man die Sequenz einer DNA-Strangs kennt, man automatisch die Sequenz des komplementären Strangs ableiten kann. Zum Beispiel, wenn ein Strang die Sequenz ATGC hat, ist der komplementäre Strang TACG.
Die Richtung der DNA-Stränge
Die beiden Stränge der DNA-Doppelhelix verlaufen antiparallel zueinander. Das bedeutet, dass sie in entgegengesetzte Richtungen orientiert sind. Jeder Strang hat ein 5'-Ende (sprich: fünf-Strich-Ende) und ein 3'-Ende (sprich: drei-Strich-Ende). Das 5'-Ende hat einen Phosphatrest, der an das 5'-Kohlenstoffatom der Desoxyribose gebunden ist, während das 3'-Ende eine freie Hydroxylgruppe (-OH) am 3'-Kohlenstoffatom der Desoxyribose hat. Ein Strang verläuft von 5' nach 3', während der komplementäre Strang von 3' nach 5' verläuft.
Diese Ausrichtung ist wichtig für die Replikation und Transkription der DNA, da Enzyme, die diese Prozesse durchführen, die DNA in einer bestimmten Richtung lesen und synthetisieren.
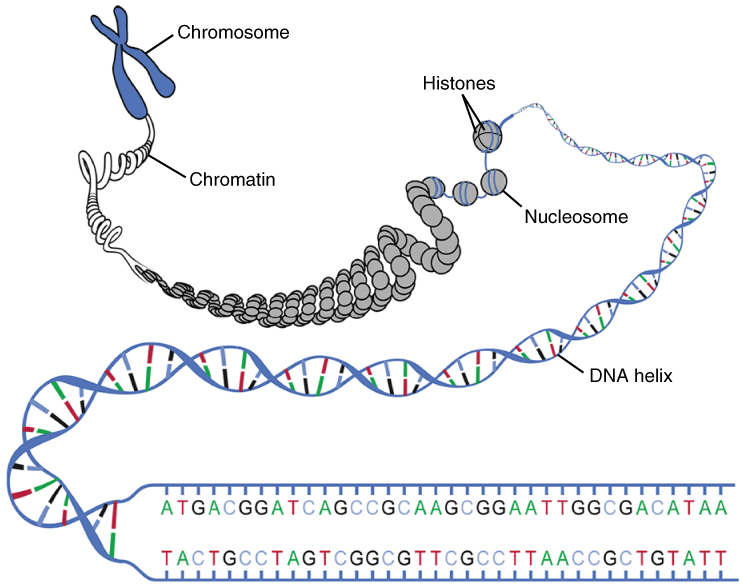
DNA im Zellkern
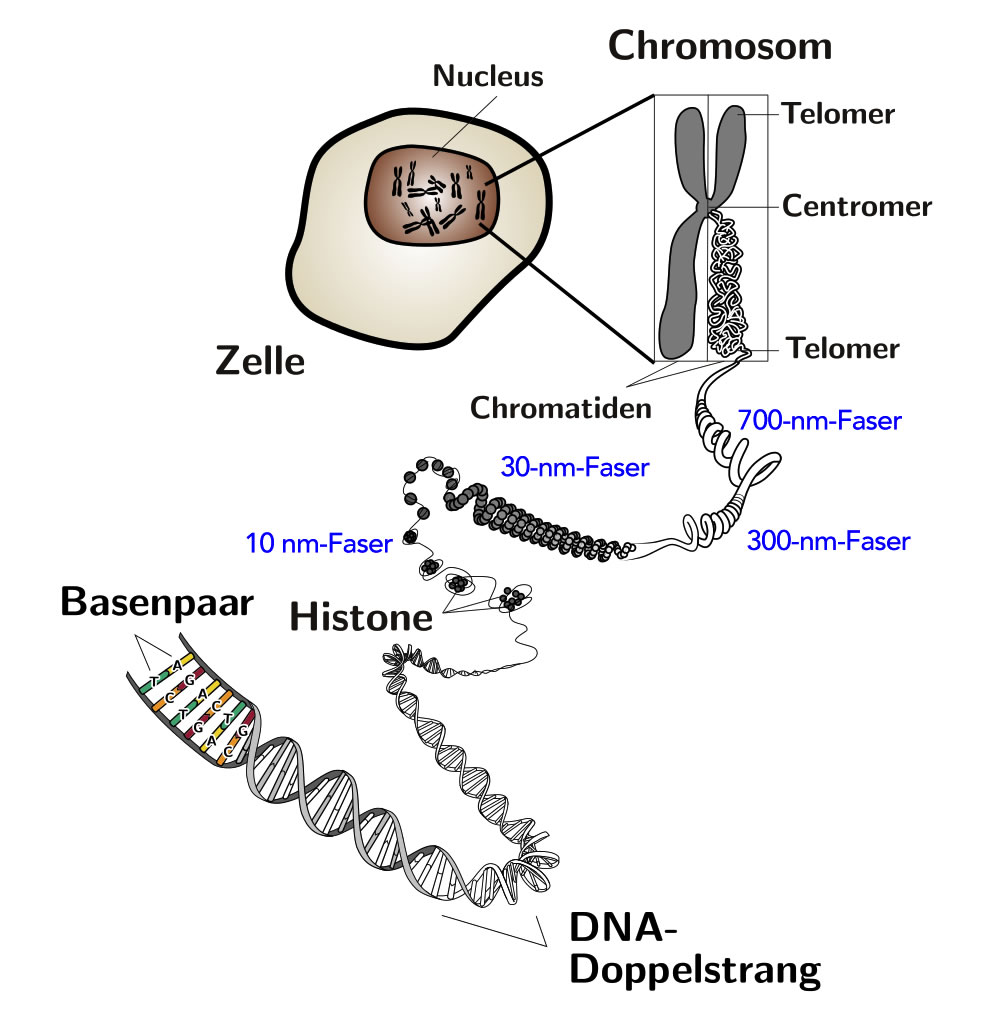
Bei Eukaryoten (Lebewesen mit Zellkern, wie Pflanzen, Tiere und Pilze) befindet sich die DNA hauptsächlich im Zellkern. Um in den Zellkern zu passen, ist die lange DNA-Kette eng um Proteine gewickelt, die als Histone bezeichnet werden. Diese Kombination aus DNA und Histonen wird als Chromatin bezeichnet.
Während der Zellteilung kondensiert das Chromatin zu sichtbaren Strukturen, die als Chromosomen bezeichnet werden. Jeder Mensch hat 46 Chromosomen, die in 23 Paaren angeordnet sind. Ein Mitglied jedes Paares wird von der Mutter und das andere vom Vater vererbt.
Die Funktion der DNA: Träger der genetischen Information
Die Hauptfunktion der DNA ist die Speicherung und Weitergabe der genetischen Information. Die Reihenfolge der Basen (A, T, G, C) codiert für die Anweisungen, die für die Herstellung von Proteinen benötigt werden. Proteine sind die Arbeitspferde der Zelle und führen eine Vielzahl von Funktionen aus, von der Katalyse biochemischer Reaktionen bis zum Aufbau von Zellstrukturen.
Der Prozess, bei dem die genetische Information der DNA genutzt wird, um Proteine herzustellen, wird als zentrales Dogma der Molekularbiologie bezeichnet und umfasst zwei Hauptschritte:
- Transkription: Die DNA-Sequenz wird in eine komplementäre RNA-Sequenz (Ribonukleinsäure) umgeschrieben. Die RNA ist ein ähnliches Molekül wie DNA, verwendet aber Uracil (U) anstelle von Thymin (T). Die RNA-Sequenz, die als messenger RNA (mRNA) bezeichnet wird, dient als Vorlage für die Proteinsynthese.
- Translation: Die mRNA-Sequenz wird von Ribosomen gelesen, die sich außerhalb des Zellkerns befinden. Die Ribosomen verwenden die mRNA-Sequenz, um die Aminosäuresequenz eines Proteins zu bestimmen. Jede Dreiergruppe von Basen (ein Codon) in der mRNA codiert für eine bestimmte Aminosäure.
DNA-Replikation
Vor der Zellteilung muss die DNA repliziert werden, um sicherzustellen, dass jede Tochterzelle eine vollständige Kopie des Genoms erhält. Die DNA-Replikation ist ein hochpräziser Prozess, der von Enzymen durchgeführt wird, die als DNA-Polymerasen bezeichnet werden.
Die Replikation beginnt damit, dass sich die Doppelhelix an einer bestimmten Stelle, dem Replikationsursprung, entwindet. Die DNA-Polymerase verwendet dann jeden Strang als Vorlage, um einen neuen, komplementären Strang zu synthetisieren. Da die DNA-Polymerase nur in 5'-nach-3'-Richtung synthetisieren kann, wird ein Strang kontinuierlich synthetisiert (der führende Strang), während der andere Strang diskontinuierlich in kurzen Fragmenten (Okazaki-Fragmente) synthetisiert wird, die später verbunden werden (der folgende Strang).
Das Ergebnis der DNA-Replikation sind zwei identische DNA-Doppelhelices, die jeweils aus einem ursprünglichen Strang und einem neu synthetisierten Strang bestehen. Dieser Prozess wird als semikonservative Replikation bezeichnet.
Mutationen
Obwohl die DNA-Replikation sehr genau ist, können Fehler auftreten, die zu Mutationen führen. Mutationen sind Veränderungen in der DNA-Sequenz. Sie können spontan auftreten oder durch äußere Einflüsse wie Strahlung oder Chemikalien verursacht werden.
Mutationen können unterschiedliche Auswirkungen haben. Einige Mutationen haben keinen Einfluss auf die Funktion des Proteins (stille Mutationen), während andere die Funktion des Proteins verändern oder ganz ausschalten können. Mutationen können sowohl positive als auch negative Auswirkungen haben. Einige Mutationen können zu Krankheiten führen, während andere zu neuen Eigenschaften führen, die einem Organismus einen Überlebensvorteil verschaffen.
Zusammenfassung
Die DNA ist ein faszinierendes und komplexes Molekül, das die Grundlage des Lebens bildet. Sie besteht aus Nukleotiden, die sich zu einer Doppelhelix anordnen. Die Reihenfolge der Basen in der DNA codiert für die genetische Information, die für die Herstellung von Proteinen benötigt wird. Die DNA wird repliziert, um sicherzustellen, dass jede Tochterzelle eine vollständige Kopie des Genoms erhält. Mutationen können die DNA-Sequenz verändern und unterschiedliche Auswirkungen auf die Funktion des Proteins haben.
Das Verständnis des Aufbaus und der Funktion der DNA ist entscheidend für das Verständnis der Biologie und Medizin. Dieses Wissen kann verwendet werden, um Krankheiten zu diagnostizieren und zu behandeln, neue Medikamente zu entwickeln und das Leben im Allgemeinen besser zu verstehen.
![Wie Ist Eine Dna Aufgebaut DNA Abiwissen • Aufbau, Bestandteile, Funktion · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2022/01/WP_DNA_Abiwissen_1_aufbau-1024x576.jpg)


![Wie Ist Eine Dna Aufgebaut DNA Aufbau • Struktur und Bausteine · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2024/04/Wordpress_DNA-Aufbau-Ue_Lina10-1024x576.jpg)
![Wie Ist Eine Dna Aufgebaut DNA einfach erklärt • Aufbau und Funktion · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2021/12/WP-Bild_DNA-Aufbau-Doppelhelix_2-1024x576.jpg)
![Wie Ist Eine Dna Aufgebaut DNA (Desoxyribonukleinsäure) • Funktion und Sequenzierung · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2020/11/WP_DNA_dna_aufbau_2-1024x576.jpg)
![Wie Ist Eine Dna Aufgebaut DNA einfach erklärt • Aufbau und Funktion · [mit Video]](https://blog.assets.studyflix.de/wp-content/uploads/2021/12/WP-Bild_Wo-befindet-sich-die-DNA-1024x576.jpg)
![Wie Ist Eine Dna Aufgebaut DNA Aufbau · Chromosomen, Nukleotid, DNA Doppelhelix · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2020/09/Bild-9-1024x576.png)
![Wie Ist Eine Dna Aufgebaut DNA Abiwissen • Aufbau, Bestandteile, Funktion · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2022/01/WP_DNA_Abiwissen_4_aufbau-1024x576.jpg)
![Wie Ist Eine Dna Aufgebaut DNA Aufbau · Chromosomen, Nukleotid, DNA Doppelhelix · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2020/09/Bild-6-1-1024x576.png)
![Wie Ist Eine Dna Aufgebaut DNA Abiwissen • Aufbau, Bestandteile, Funktion · [mit Video]](https://d1g9li960vagp7.cloudfront.net/wp-content/uploads/2022/01/WP_DNA_Abiwissen_7_dna-rna-1024x576.jpg)