Python Doppelte Einträge Aus Liste Entfernen

In der Welt der Programmierung, insbesondere in Python, begegnen wir häufig dem Problem, doppelte Einträge aus Listen zu entfernen. Diese Aufgabe erscheint auf den ersten Blick trivial, birgt aber bei näherer Betrachtung eine Vielzahl von Lösungsansätzen und impliziert wichtige Überlegungen hinsichtlich Effizienz, Speicherverbrauch und Datenintegrität. In diesem Artikel werden wir verschiedene Methoden zur Entfernung von Duplikaten aus Python-Listen untersuchen, ihre jeweiligen Vor- und Nachteile analysieren und die Implikationen für verschiedene Anwendungsfälle beleuchten.
Die Grundlagen: Listen in Python
Bevor wir uns den spezifischen Techniken widmen, ist es wichtig, die Natur von Listen in Python zu verstehen. Eine Liste ist eine geordnete und veränderbare Sammlung von Elementen. Diese Elemente können unterschiedlichen Datentyps angehören (Integer, Strings, Objekte, etc.). Die Flexibilität von Listen macht sie zu einem unverzichtbaren Werkzeug in der Python-Programmierung. Allerdings führt diese Flexibilität auch dazu, dass Listen Duplikate enthalten können, was in manchen Situationen unerwünscht ist.
Methoden zur Duplikatsentfernung
Es gibt mehrere Strategien, um Duplikate aus einer Python-Liste zu entfernen. Jede Methode hat ihre eigenen Vor- und Nachteile, die sorgfältig abgewogen werden müssen, um die optimale Lösung für den jeweiligen Anwendungsfall zu finden.
1. Die Verwendung von Sets
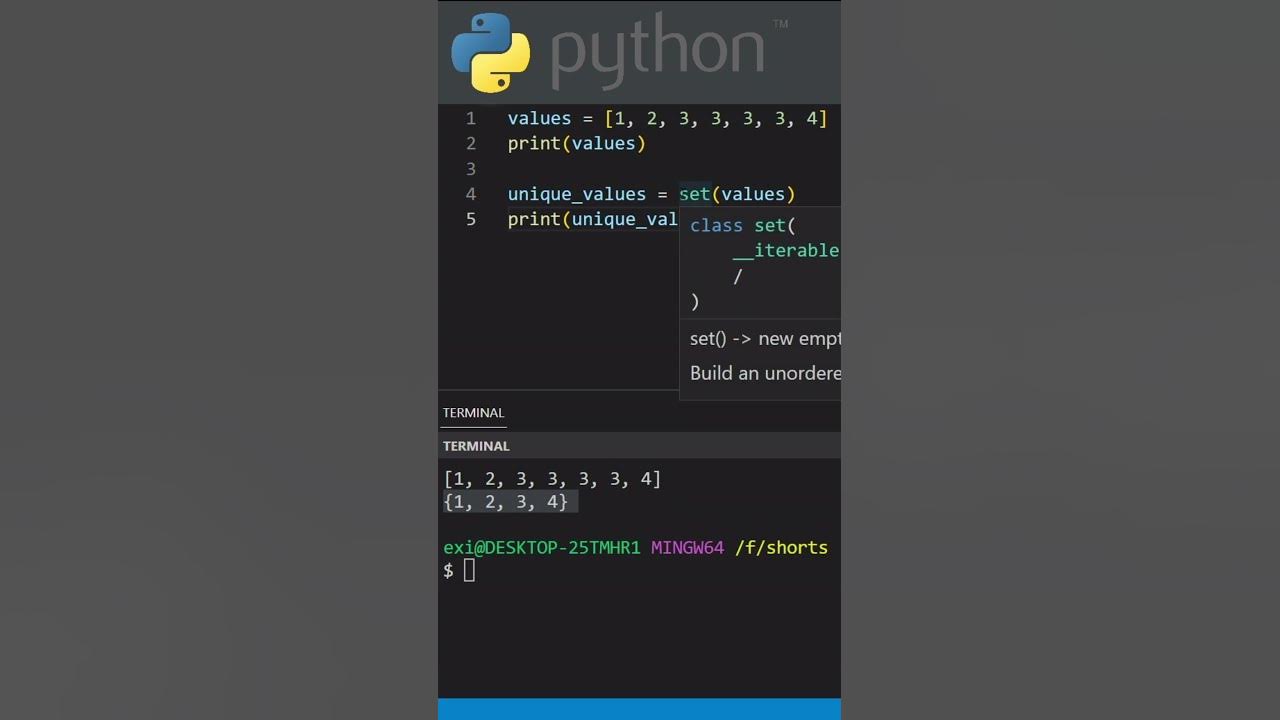
Die einfachste und oft effizienteste Methode ist die Verwendung von Sets. Ein Set ist eine ungeordnete Sammlung von eindeutigen Elementen. Durch die Konvertierung einer Liste in ein Set werden alle Duplikate automatisch entfernt. Anschließend kann das Set wieder in eine Liste umgewandelt werden, um die ursprüngliche Datenstruktur beizubehalten. Dies ist jedoch nur dann praktikabel, wenn die Reihenfolge der Elemente in der Liste keine Rolle spielt.
meine_liste = [1, 2, 2, 3, 4, 4, 5]
meine_liste_ohne_duplikate = list(set(meine_liste))
print(meine_liste_ohne_duplikate) # Output: [1, 2, 3, 4, 5] (Reihenfolge kann variieren)
Vorteile: Einfach, schnell, prägnant.
Nachteile: Die ursprüngliche Reihenfolge der Elemente wird nicht beibehalten. Funktioniert nicht mit nicht-hashbaren Objekten in der Liste (z.B. Listen selbst).
2. Listen-Comprehension mit Bedingung
Eine weitere Möglichkeit ist die Verwendung einer Listen-Comprehension in Kombination mit einer Hilfsdatenstruktur, um bereits gesehene Elemente zu verfolgen. Diese Methode ermöglicht es, die ursprüngliche Reihenfolge der Elemente beizubehalten.
meine_liste = [1, 2, 2, 3, 4, 4, 5]
gesehen = set()
meine_liste_ohne_duplikate = [x for x in meine_liste if x not in gesehen and not gesehen.add(x)]
print(meine_liste_ohne_duplikate) # Output: [1, 2, 3, 4, 5] (Reihenfolge beibehalten)
Vorteile: Behält die ursprüngliche Reihenfolge bei.
Nachteile: Etwas komplexer als die Set-Methode. Kann bei sehr großen Listen ineffizienter sein, da die `in`-Operation auf Sets eine durchschnittliche Zeitkomplexität von O(1) hat, aber die Listen-Comprehension iteriert über die gesamte Liste.
Erklärung der Codezeile: Der Ausdruck `x not in gesehen and not gesehen.add(x)` nutzt die Tatsache aus, dass `gesehen.add(x)` immer `None` zurückgibt. Da `None` als `False` interpretiert wird, wird `not None` zu `True`. Dadurch wird sichergestellt, dass `x` nur dann zur neuen Liste hinzugefügt wird, wenn es noch nicht in `gesehen` enthalten ist.
3. Verwenden eines OrderedDict
Das `OrderedDict` aus dem Modul `collections` (vor Python 3.7) bzw. `dict` ab Python 3.7 (Dictionaries behalten ihre Einfügungsreihenfolge bei) kann ebenfalls verwendet werden, um Duplikate zu entfernen und die Reihenfolge beizubehalten.
from collections import OrderedDict
meine_liste = [1, 2, 2, 3, 4, 4, 5]
meine_liste_ohne_duplikate = list(OrderedDict.fromkeys(meine_liste))
print(meine_liste_ohne_duplikate) # Output: [1, 2, 3, 4, 5] (Reihenfolge beibehalten)
Ab Python 3.7 kann man einfach ein Dictionary verwenden:
meine_liste = [1, 2, 2, 3, 4, 4, 5]
meine_liste_ohne_duplikate = list(dict.fromkeys(meine_liste))
print(meine_liste_ohne_duplikate)
Vorteile: Behält die ursprüngliche Reihenfolge bei. Effizient.
Nachteile: Benötigt den Import des `OrderedDict`-Moduls (falls Python < 3.7) oder ist leicht umständlicher als die Set-Methode.
4. Iteration und bedingtes Hinzufügen
Eine explizite Iteration über die Liste und das bedingte Hinzufügen von Elementen zu einer neuen Liste ist eine weitere Möglichkeit, Duplikate zu entfernen. Diese Methode bietet die größte Kontrolle, ist aber auch die umständlichste.
meine_liste = [1, 2, 2, 3, 4, 4, 5]
meine_liste_ohne_duplikate = []
for element in meine_liste:
if element not in meine_liste_ohne_duplikate:
meine_liste_ohne_duplikate.append(element)
print(meine_liste_ohne_duplikate) # Output: [1, 2, 3, 4, 5] (Reihenfolge beibehalten)
Vorteile: Behält die ursprüngliche Reihenfolge bei. Einfach zu verstehen.
Nachteile: Ineffizient für große Listen, da die `in`-Operation auf Listen eine Zeitkomplexität von O(n) hat. Für jede Iteration über die ursprüngliche Liste wird die neue Liste durchsucht, was zu einer quadratischen Zeitkomplexität O(n^2) führt.
Performance-Betrachtungen
Die Wahl der optimalen Methode zur Duplikatsentfernung hängt stark von der Größe der Liste und der Bedeutung der Reihenfolge ab. Für kleine Listen ist die Set-Methode oft ausreichend schnell und einfach. Für größere Listen, bei denen die Reihenfolge wichtig ist, sind die Listen-Comprehension-Methode oder die OrderedDict-Methode (oder Dictionary-Methode ab Python 3.7) in der Regel effizienter als die explizite Iteration. Es ist ratsam, die Performance verschiedener Methoden mit `timeit` zu testen, um die beste Lösung für den spezifischen Anwendungsfall zu ermitteln.
Komplexere Datentypen
Die vorgestellten Methoden funktionieren gut für Listen, die einfache Datentypen wie Integer oder Strings enthalten. Bei Listen, die komplexere Objekte enthalten (z.B. eigene Klasseninstanzen), muss die Definition von "Duplikat" genauer definiert werden. Oft muss die `__eq__`-Methode der Klasse überschrieben werden, um zu definieren, wann zwei Instanzen als gleich betrachtet werden. Die Set-Methode erfordert zudem, dass das Objekt hashable ist, d.h. die `__hash__`-Methode muss ebenfalls implementiert werden.
Die Wahl der richtigen Methode zur Duplikatsentfernung ist ein Paradebeispiel dafür, wie wichtig es ist, die Trade-offs zwischen Lesbarkeit, Performance und Speicherverbrauch zu verstehen. Es gibt keine "One-Size-Fits-All"-Lösung, sondern eine sorgfältige Abwägung der jeweiligen Anforderungen.
Zusammenfassung
Die Entfernung von Duplikaten aus Python-Listen ist eine häufige Aufgabe mit vielfältigen Lösungsansätzen. Die Set-Methode ist einfach und effizient, wenn die Reihenfolge keine Rolle spielt. Die Listen-Comprehension-Methode und die OrderedDict-Methode (bzw. Dictionary-Methode ab Python 3.7) ermöglichen die Beibehaltung der Reihenfolge. Die explizite Iteration ist flexibel, aber ineffizient für große Listen. Die Wahl der optimalen Methode hängt von der Größe der Liste, der Bedeutung der Reihenfolge und der Komplexität der Datentypen ab.